
深度学习中知识蒸馏研究综述
1. 摘要
在人工智能迅速发展的今天,深度神经网络广泛应用于各个研究领域并取得了巨大的成功,但也同样面临着诸多挑战。首先,为了解决复杂的问题和提高模型的训练效果,模型的网络结构逐渐被设计的深而复杂,难以适应移动计算发展对低资源、低功耗的需求。知识蒸馏最初作为一种从大型教师模型向浅层学生模型迁移知识、提升性能的学习范式被用于模 型压缩。然而随着知识蒸馏的发展,其教师-学生的架构作为一种特殊的迁移学习方式,演化出了丰富多样的变体和架构,并被逐渐扩展到各种深度学习任务和场景中,包括计算机视觉、自然语言处理、推荐系统等等。另外,通过神经网络模型之间迁移知识的学习方式,可以联结跨模态或跨域的学习任务,避免知识遗忘;还能实现模型和数据的分离,达到保护隐私数据的目的。知识蒸馏在人工智能各个领域发挥着越来越重要的作用,是解决很多实际问题的一种通用手段。本文将近些年来知识蒸馏的主要研究成果进行梳理并加以总结,分析该领域所面临的挑战,详细阐述知识蒸馏的学习框架,从多种分类角度对知识蒸馏的相关工作进行对比和分析,介绍了主要的应用场景,在最后对未来的发展趋势提出了见解。
2. 主要内容
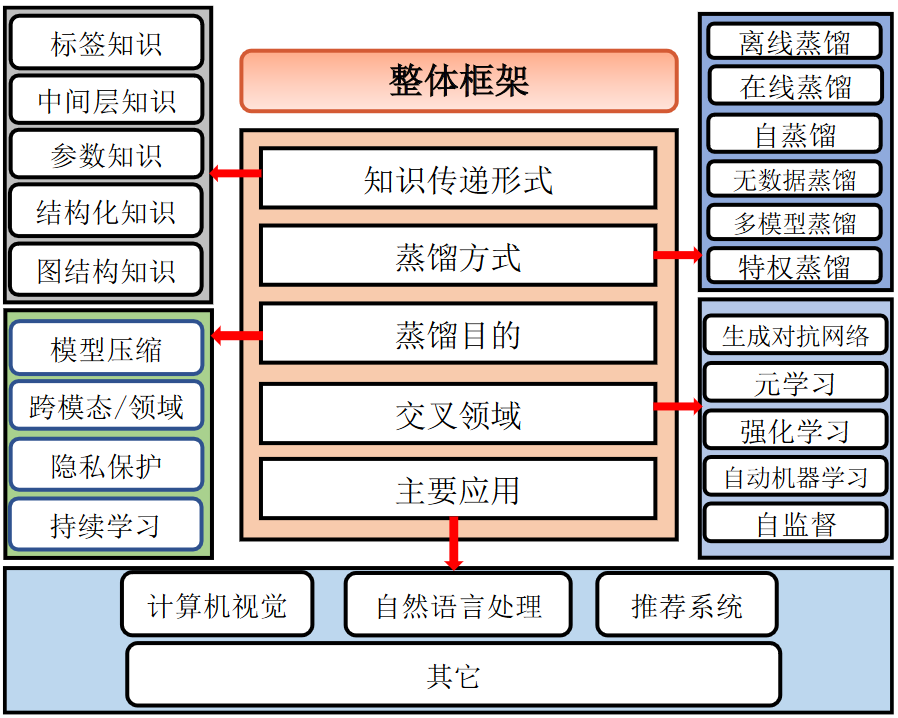
1. 整体框架
知识蒸馏本质上属于迁移学习的范畴,其主要思路是将已训练完善的模型作为教师模型,通过控制“温度”从模型的输出结果中“蒸馏”出“知识” 用于学生模型的训练,并希望轻量级的学生模型能够学到教师模型的“知识”,达到和教师模型相同的表现。
2. 知识传递形式
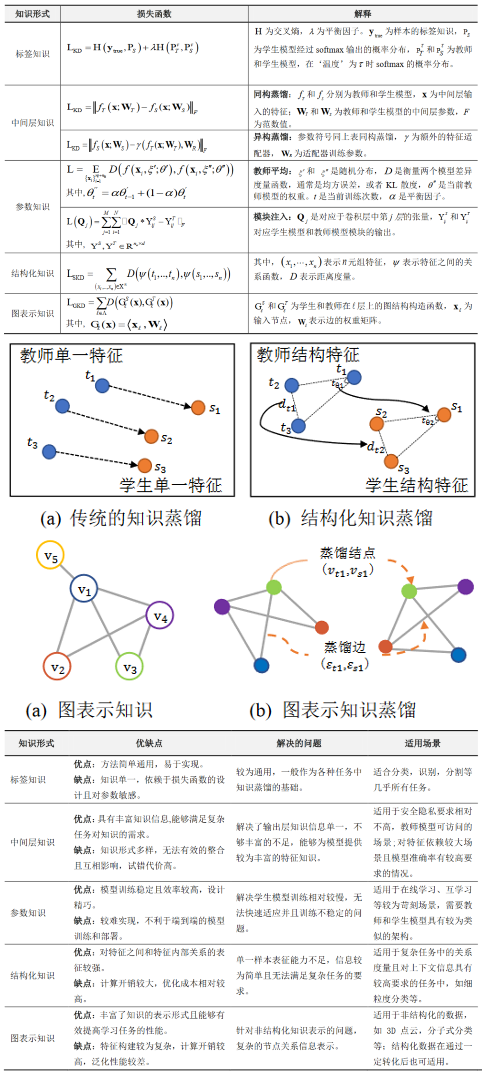
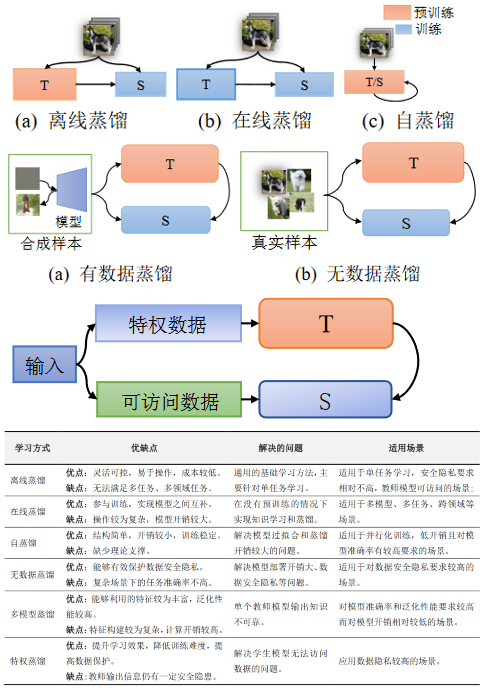
3. 蒸馏方式
4. 蒸馏目的
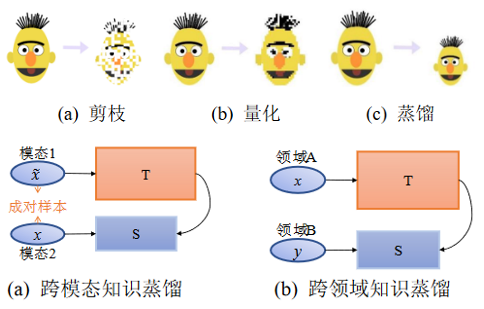
传统的深度学习模型很容易受到隐私攻击。例如,攻击者可以从模型参数或目标模型中恢复个体 的敏感信息。因此,出于隐私或机密性的考虑,大 多数数据集都是私有的,不会公开共享。特别是在处理生物特征数据、患者的医疗数据等方面。而且, 企业通常也不希望自己的私有数据被潜在竞争对 手访问。因此,模型获取用于模型训练优质数据,并不现实。对于模型来说,既希望能访问这些隐私 数据的原始训练集,而又不能将其直接暴露给应 用。因而,可以通过教师-学生结构的知识蒸馏来隔离的数据集的访问。让教师模型学习隐私数据,并 将知识传递给外界的模型。
持续学习(Continual Learning) 是指一个学习 系统能够不断地从新样本中学习新的知识,并且保存大部分已经学习到的知识,其学习过程也十分类 似于人类自身的学习模式。但是持续学习需要面对 一个非常重要的挑战是灾难性遗忘,即需要平衡新知识与旧知识之间的关系。
5. 交叉领域
知识蒸馏和GANs 结合较为简单且可以在 GAN 模型的不同模块上实现蒸馏,主要可以分为3 类:对生成器蒸馏,对判别器蒸馏和同时对生成器和判别器蒸馏
强化学习(Reinforcement Learning, RL),也被称为增强学习,主要用于描述和解决智能体在与环境的交互过程中通过学习策略以达到获取最大化回报的目标问题,深度 强 化 学 习 (Deep Reinforcement Learning, DRL) 模型的已经被广泛应用于各个领域,DRL 在应用过程中,深度模型需要通过与环境大量的交互获取奖励来更新智能体的网络参数,最终获得较高水平的表现。这使得模型的训练开销非常巨大。因此,研究人员将知识蒸馏应用于DRL,期望辅助模型训练以提升模型的训练效果并且实现深度模型的轻量化。
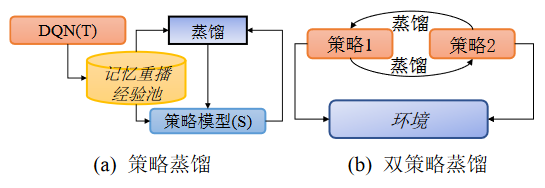
深度强化教师模型将经验值存到记忆重播池中,学生模型从策略池中学习教师模型的经验。双策略模型的两个模型从环境中学习经验并互相蒸馏知识。
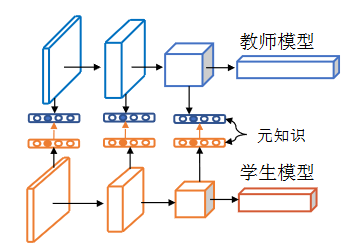
在教师和学生模型中构建 “元知识”用于辅助学生训练。
自动机器学习(Auto Machine Learning, AutoML)是将机器学习整个流程通过端到端的方式实现自动化的过程。传统机器学习模型需要完成数据采集、数据预处理、模型优化和应用部署等步骤;而完成这些步骤需要花费大量的精力进行算法和模型的选择。AutoML 从传统机器学习模型出发,在特征工程、模型构建和超参优化三方面实现自动化并给出了端到端(End-to-End)的解决方案。
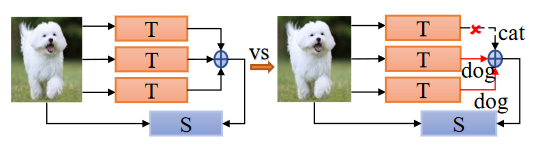
左图为传统蒸馏从多个教师模型学习知识并集成,右图为自动机器学习, 从教师模型学习并自动搜索出最准确的知识并集成。
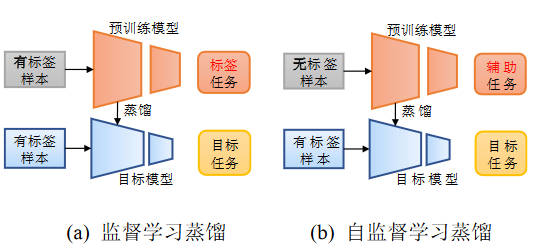
传统的监督学习的蒸馏在标签数据集上构建预训练模型(标签任务),而自监督学习蒸馏则是在无标签数据集上训练并‘总结’出知识(辅助任务),用于目标模型的训练。